
Effective risk monitoring for banks means keeping up with a rapidly changing, dynamic world. Modern risk management systems must break from patterns of the past to recognize daily changes in the threat environment. The challenge is to stay ahead in the constant technical arms-race between good guys and bad guys, who develop evasion and detection techniques in an evolutionary interplay. We see that now with the novel coronavirus (COVID-19) pandemic, as criminals seek to take advantage of the situation for their own monetary benefit. Quantifind offers solutions to detect and fight this pandemic of fraud as it evolves.
Fraud During Natural Disasters
Most fraud detection professionals are only too aware of scams associated with natural disasters. Certain schemes, such as fraudulent hurricane relief funds, leverage fear, noise, and chaos to make money off of desperate victims and unsuspecting donors. Sadly, the COVID-19 pandemic is no different, and has brought out the worst from malevolent individuals and organizations, who are looking to turn the crisis into a fraudulent payday.
Examples of these emerging bad actors abound, including price gouging retailers, counterfeit masks, bogus charities, phishing scams, and politicians spinning the crisis for their own personal motives. In this post, we will focus on fraudulent entities perpetuating medical scams that pose a risk to their partners, for example financial institutions that may unwittingly facilitate them. Quantifind provides useful services to systematically expose such frauds, and here we have a detailed case study for one particular fraud: MMS (Miracle Mineral Solution), whose proponents effectively sell the act of drinking bleach as a cure-all for coronavirus among many other diseases.
AI-Driven Graph Enrichment
The goal of Quantifind’s technology is to start with a seed entity or concept and produce a much larger set of closely related entities, as well as additional high-confidence contextual information about each. This allows institutions looking to assess their risk exposure to cast a wide net and ensure that they are not compromised, even at second degree. This idea of an “exposure graph” is captured in the Related Entities feature of Quantifind’s Entities search product and includes both social and corporate connections. Here, we lay out the process of how developing an exposure graph works in the context of the Miracle Mineral Solution coronavirus scam.
SEEDING
Any investigation starts with a set of seed terms or entities. One starting point could be the pre-identified entities that the FTC and FDA have already named have already named as perpetuating coronavirus related fraud, and we can then expand those into a full graph network. We could also start more organically by mining social media for signals of fraudulent schemes that are percolating into consumer awareness. For example, tweets like this like this, which are skeptical of official FDA guidance:
“Question: Has anyone tried MMS “miracle mineral solution”? It’s safely used in a wide variety of industries like food processing. Hikers use it to disinfect water. Yet the FDA warns against it, media blitz saying Q followers are drinking bleach. The attacks against MMS says a lot.”
Or expert warnings like this:
“1/2 Some fringe groups are spreading misinformation over social media that MMS — or miracle mineral solution — can cure the #coronavirus. It won’t. MMS is just potent bleach by another name. Here’s prior FDA guidance. MMS is now trending on @Google search.”
The FDA guidance document in reference is titled “FDA warns consumers about the dangerous and potentially life threatening side effects of Miracle Mineral Solution”. From here, we can quickly find evidence of intestinal problems and even deaths associated with MMS. Not surprisingly, this pseudo-scientific remedy has a fraudulent history of being claimed as a cure-all for other diseases, including cancer, autism, malaria, and HIV, where there have been several schemes run targeting desperate victims in Africa. COVID-19 is simply the latest in a long line of opportunities for the fraudsters to repeat their script.
TOPIC AMPLIFICATION
To fully assess the exposure to a particular scheme, it helps to first expand the definition to make sure that all aliases and related terms are covered in our search. Otherwise, closely related variants of the scheme will be missed when we canvass for related entities. Starting with the seed phrase “Miracle Mineral Solution” we are able to use co-occurrence in unstructured data to “build out” the topic in question:
Primary term: Miracle Mineral Solution
Aliases: MMS, Miracle Mineral Supplement, Master Mineral Solution, …
Related terms: Chlorine Dioxide, CD Protocol, Bleach Cult, DMSO, …
Other cure alls: Silver Solution, Colloidal Silver, …
Finding aliases is not just an exercise in expansion, it is also an exercise in tracking and monitoring. Similar to when a fraudster picks up and leaves for a new town after wearing out their welcome, an online fraudster will change the name of their scheme, for example from “Miracle Mineral Solution” to “Master Mineral Solution,” keeping the same acronym. Of course, the fraudsters also change their target audience and platforms regularly, mutating to survive, even after they have been caught in one particular context.
RELATED ENTITIES
With key terms in hand, we can then automatically generate a list of related entities by mining the same unstructured data sources, including news and social media. We do this with named entity recognition (NER), extracting organizations and individuals from text, and scoring entities by how likely their presence in a document is to predict the seed topic in question. This lets us build the “cast of characters” across thousands of news articles instantaneously. We can then classify those individuals and organizations into good-guy and bad-guy roles by using natural language processing (NLP) and machine learned rules from appropriate training data. This process of generating lists for assessing risk exposure generates huge gains in efficiency compared to an investigator going through Google manually.
Here is an example list:
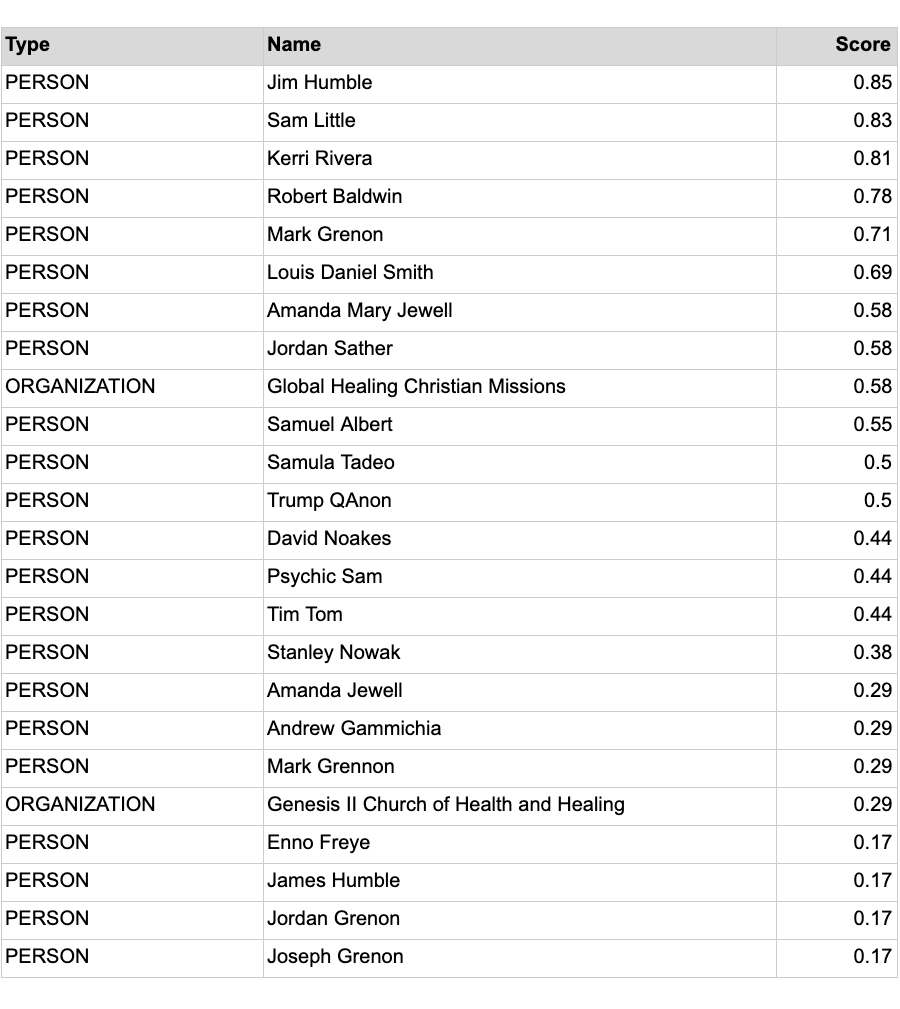
By generating this list of entities, we are essentially answering the questions: Who is the cast of characters closely associated with this collection of schemes? And what are their connections in turn? To completely “develop” the graph of interest, we can iterate on these last few steps, and truncate the process when the predictive score becomes negligible and we are too far afield of our original focus. Depending on the scheme in question, it is not atypical to start with a handful of seed items and end up with hundreds of potential entities that represent the same risk factor.
ENRICHED ENTITIES
With the topic-related entities generated, we can then go deep on each entity, finding metadata, other risk factors, and related entities to that individual or organization, both from news data and beneficial ownership databases. Quantifind’s Entities product does exactly this, allowing a user to search for all high-confidence risk factors in a user friendly interface.
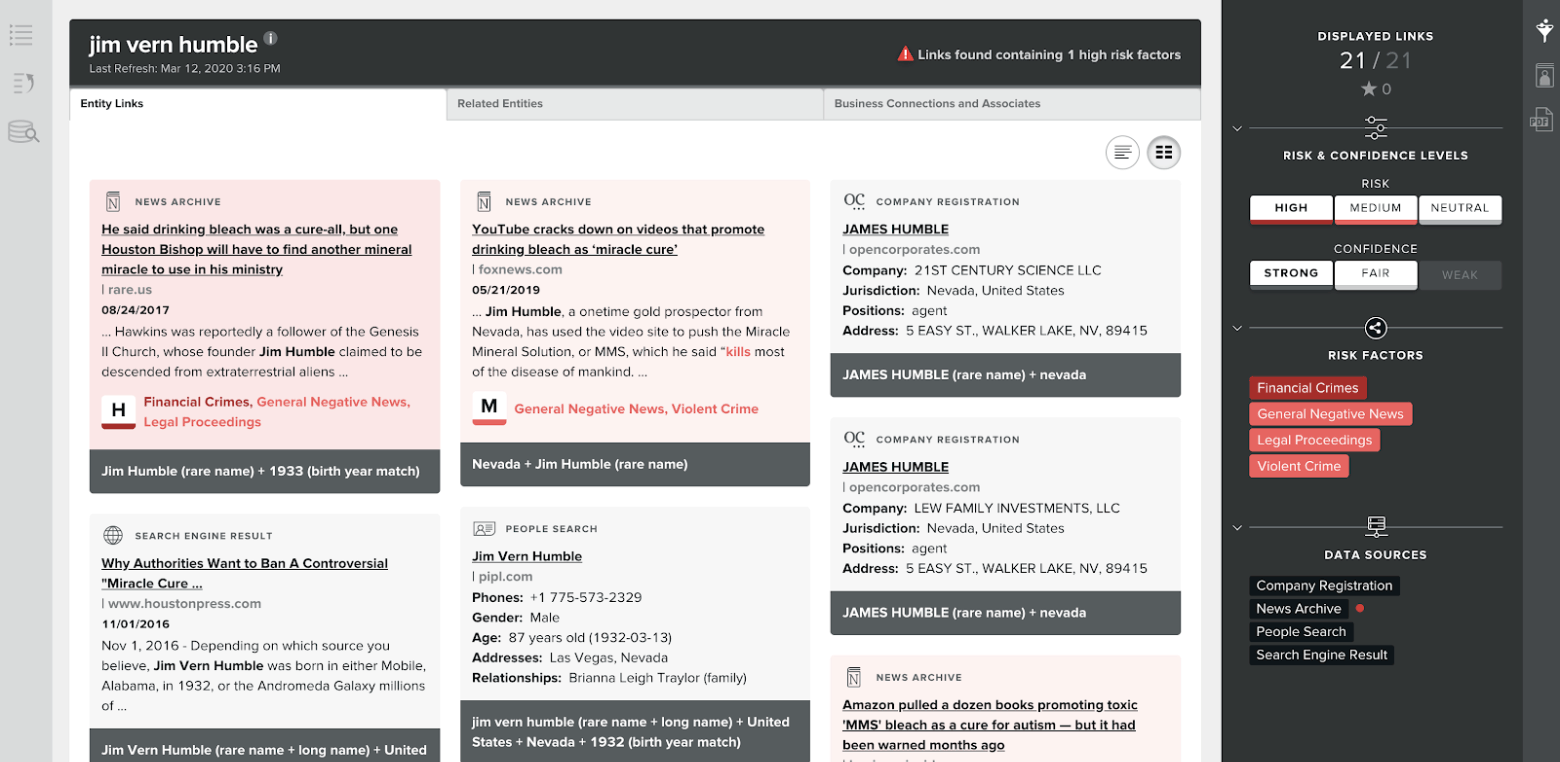
In the screenshots below we show a search for Jim Humble, the founder of MMS. The product reveals this individual’s other risk factors (including financial crimes, violent crime), ownership of organizations (including “21st Century Science, LLC” and “Lew Family Investments LLC”), metadata (birthday and phone number), and related entities (including business partners such as Richard Johnson, and co-occurrence with Shane Hawkins and Genesis II Church, who sold the harmful product as sacraments).
Note that crimes and certain risk factors tend to cluster, and it is not surprising that we see certain high-risk organizations, like the Church of Scientology, associated with the entity. Other entities in the above list have ties to other potentially fraudulent topics, including QAnon (online misinformation) and ICO’s (cryptocurrency offerings, known for duping investors). We can also discover ties in the graph to prominent politicians (or PEP, politically exposed person) who are using their influence to spread misinformation on the topic.
HIGHLIGHT DISCOVERIES AND CLIENT USE CASES
Finally, after having amplified the initial seed into a large set of enriched entities, multiple opportunities emerge to highlight novel discoveries in the resulting graph. The first is in finding “net new” fraudsters that are still active, as opposed to finding only those that are “old news” and have already been processed by law enforcement. Second, we can find connections between “rings” or sub-graphs that were previously considered unconnected. By finding these missing links, we can help increase the efficiency of investigations by clustering them appropriately.
Ultimately, we can provide this extracted entity graph database to one of our clients, allowing them to cross-reference their database and discover entities that “match back” to their internal data, including client lists or existing cases, indicating that the institution in question is potentially exposed. The following groups can all benefit from this data useful in rooting out criminal behavior while also limiting their liability:
Banks: Financial institutions could ask themselves, “Are we facilitating financial transactions in these fraudulent schemes?” and screen their customer data and existing internal cases accordingly.
Law Enforcement and Regulators: Government entities could ask themselves, “Are we missing any leads in our investigation and communication?” and cross-link this open source data with their cases to expand and unify their investigations.
Retailers: Online and physical sellers and advertisers could ask themselves “Are we selling products that perpetuate or promote these schemes?” This is especially true for marketplaces, with less control and visibility of their inventory. Their restrictions should look beyond what the regulators are looking for and implement a data-driven degree of self-policing as well. Although many companies are saying the right things, there is still evidence that they are not always implementing their policies effectively, including examples from Amazon (selling this despite this statement), Ebay (selling this and this), and Google (selling this, not flagging news sites like this).
Social Media: Although this may be the trickiest depending on the scheme, social media platforms could ask themselves, “Are we allowing our users to promote fraudulent schemes?” Again, there is evidence that, despite public efforts, these channels do not always effectively monitor their content, including Youtube (promoting this despite this statement), Twitter (allowing this, this, and conspiracy theorists like this) and Facebook (this, this, this). Of course, there is an ongoing debate in a much wider context on misinformation and which organizations should bear the responsibility, but methods like those we outline here could potentially help identify and eliminate the threats to our public health that are on the less controversial side of the spectrum.
Principles of Continuous Risk Tracking
In performing the above process, there are certain key principles Quantifind follows to ensure effective risk monitoring:
- Fresh Data: An adaptive risk monitoring system is useless unless the data behind it is continuously updated. Quantifind’s products bring in news data and also perform programmatic search to ensure that we are able to capture new risk signals as soon as they appear.
- Unstructured Capabilities: Most fresh data, especially new data signals that have not been anticipated, naturally arrives in an unstructured form. Systems that ignore the ability to extract signals from unstructured text data will simply miss those signals until it is too late. Quantifind’s unstructured capabilities set us apart.
- Comprehensive: Risks never manifest in a single data set alone. Having diverse sets of data lets allows us to see the whole picture and find missing links.
- Updating Signals: If we are not continuously monitoring for new entities and terms, the fraud is likely to evolve beyond our detection. Similar to tracking a pandemic, Quantifind has the ability to set up systems to learn on the fly when there have been new outbreaks and mutations, then feed this knowledge back into the system.
- Quality: Any automated graph-building system needs to ensure that the basic components of the graph are high quality. Are the graph connections confident, i.e. is it the same entity? Are the risk factors relevant and also accurate? Much of our work at Quantifind is building algorithms to perform these basic foundational functions, which in turn allow the advanced graph analytics to take place at all.
