
The sanctions landscape is as dynamic as ever, as sanctioning becomes an increasingly prevalent mechanism to impose pressure on adversarial regimes, and with a broader range of goals. It has never been more challenging for financial institutions to avoid falling afoul of compliance regulations. Yet the tools they tend to rely upon for sanctions screening are notoriously dated and inaccurate.
Consider that legacy sanctions screening solutions are generating thousands of false positives for every valid sanctions alert, requiring banks to employ large teams of analysts around the globe to manually review and reconcile every alert to find the real non-compliance risks buried among the false positives.
The hazards are twofold. Banks not only risk missing true-positive alerts in all the noise. The false positives can also cause repeated disruptions in services for customers, and particularly for those with the misfortune of having a name similar to that of a person or company on a sanctions or watch list.
First Things First: The Role of Sanctions Data
High-quality sanctions data is imperative for reliable screening. Rigorous data quality assurance procedures should be applied, with independent auditing for completeness and accuracy. Granular tagging and taxonomy allow for a greater degree of search configuration, helping mitigate irrelevant alerts.
According to David Hodgson, Head of Content Strategists for Dow Jones Risk & Compliance, sanctions data used for screening should ideally be enriched with original script names, secondary identifiers, BICs, vessel data, linked relationships with other people or entities, and source links. There should be coverage of non-English lists, the ability to decipher and codify badly formatted lists, and to cover the EU and OFAC 50% rules. Depending solely on the original free lists may not be as simple as it first appears; in some lists removals are not readily identifiable, the EU lists are not easily readable, and some lists are formatted in such a way that they cannot be extracted or copy/pasted. Finally, screening efforts should have awareness of errors by the regulators themselves such as incorrect names or associated entities, duplicate names, incorrect dates, inadvertent removals.
Relying solely on rudimentary algorithms for name matching Is causing false positives
The primary culprit behind a high false positives rate tends to be reliance on only rudimentary name matching techniques. String distance and other simple algorithms such as Levenshtein, Jaro-Winkler, or Longest Common Substring can reduce the risk of false negatives. They cast a wide net that together with a low match threshold that causes alerts for lots of name spelling variations. False negatives are indeed reduced, but at the cost of huge volumes of false positives that human analysts need to manually reconcile. As a result, banks are implementing a patchwork of solutions to try to fill the decisioning gaps as they emerge, but this approach has proven unsustainable.
Consider the example of Jorge Jesus Rodriguez Gomez from the OFAC sanctions list:
| Last Name: RODRIGUEZ GOMEZ Program: VENEZUELA First Name: Jorge Jesus Citizenship: Venezuela Date of Birth: 09 Nov 1965 Gender: Male a.k.a. strong RODRIGUEZ, Jorge a.k.a. strong RODRIGUEZ GOMEZ, Jorge J a.k.a. strong JORGE J., Rodriguez Gomez a.k.a. strong JORGE JESUS, Rodriguez Gomez |
|---|
His given names, family names, and aliases are comprised of common names in Venezuela and in dozens of other countries around the world. Among the real people that could be expected to generate an alert are Jorge Rodriguez MD, the TV doctor, Jorge Rodriguez the minor league baseball player, and Jorge Rodriguez the business executive.
String distance matching algorithms enable fuzzy matching that improves recall, but in doing so can generate alerts for names with several common similar variations:
| Jorge Rodriguez Jesus Rodriguez George Rodriguez | Jorge Rodrigues Jesus Rodrigues George Rodrigues | Jorge Gomez Jesus Gomez George Gomez | Jorge Gomes Jesus Gomes George Gomes |
|---|
There are as many as 250,000 people with one of these names around the world, and each has the potential for their banking activity to repeatedly trigger alerts.
False positives can be significantly reduced with a more sophisticated, data-driven approach
How can we better automate the decisions behind entity matches? When is a match not a true match? While there will always be match decisions that are difficult to automate, the burden posed on analyst teams by large volumes of false positives can be significantly reduced with a more sophisticated and quantitative approach.
Performing advanced analytics on all available relevant data about a particular entity match pair enables a quantitative, probabilistic assessment of entity match and non-match confidence. A confidence-based scoring approach backed up by advanced analytics is more predictive of actual match or non-match likelihood, and has been shown to automatically eliminate over 75% of the false positives generated when using only rudimentary algorithms—without missing any true-positive results. For those alerts that still require human review, purpose-built investigations and reporting tools that leverage adverse media and other sources can be brought to bear to make the alerts management and investigations process over 50% more efficient.
Methods contributing to accurate match and non-match confidence scoring include advanced name parsing, cultural awareness, global name rarity, global name variants, and AI-powered fuzzy matching models to name a few. False positives can be more reliably identified when a) all relevant known entity information is considered and weighted properly in a match, and b) match candidates are excluded if data analysis exhibits strong confidence in a non-match.
In modeling data relevance and entity match confidence, “black box” modeling is replaced with a “clear box” approach for transparent model configuration, validation, and governance. Models are trained over tens of millions of public-domain samples, and common public training data is leveraged to build entity matching models. Native language modeling replaces machine translation for far more accurate interpretation of non-English content.
Consider the information leveraged by intelligent entity matching and how it contributes to entity matching accuracy–as compared to a string matching-only approach–for the following example from the OFAC Foreign Sanctions Evaders list:
| BEKTAS, Halis; DOB 13 Feb 1966; citizen Switzerland; Passport X0906223 (Switzerland) (individual) [SYRIA] [FSE-SY]. RIXO INTERNATIONAL TRADING LTD., Lindenstrasse 2, Baar 6340, Switzerland; Website http://www.rixointernational.com [SYRIA] [FSE-SY]. |
|---|
| Linguistic Group | Central Asian |
| Name and Address Parsing | Bektas can be a first name or last name |
| Global Name Rarity | Halis Bektas is a very rare name in Switzerland Halis Bektas is a common name in Turkey |
| Global Name Variants | Halil, Halit, and Halid are not as likely to be matches because they are not name variants of Halis |
| Advanced Fuzzy Matching | The following phonetic matches to Bektas should be considered: Bektaš Бектас Bektaş Bektash |
| Organization Matching | Rixo International Trading Ltd. is NOT a match to Rix International LLC. “International”, “Trading”, and “Ltd.” are properly weighted such as not to match with other organizations containing these common tokens. |
| Adverse Media Screening | Adverse media screening results can complement watchlist search to add corroborating evidence of a match. Native language modeling ensures that interpretation of non-English content does not rely on inaccurate machine translations. |
| Automated Programmatic Search | The sanctioned Halis Bektas is a different person from Halis Bektaş, the licensed real estate appraiser in Ankara. |
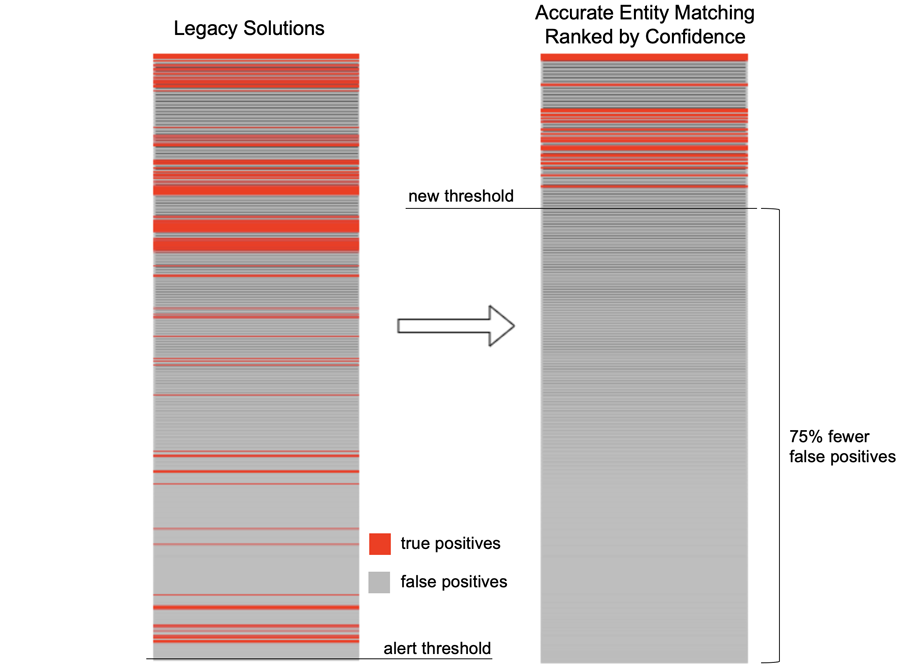
The results: 75% fewer false positives and a much smaller burden for analysts
The diagram below illustrates the contrast between the performance of legacy sanctions screening algorithms and a more advanced approach:
Sanctions Screening Alerts
In addition, these new technologies can supercharge existing sanctions screening with KYC and adverse media systems. Linking with adverse media can indicate the true match confidence and generate a detailed report on the successfully blocked customer or counterparty. This enables a broader review by an FIU of the network relationship linked to the sanctioned entity, and establishes whether broader action is required in the form of SAR filings and customer exit decisions. Adverse media screening can also even be used to provide alerts to entities at high risk of being put on a sanctions list in advance of their formal listing.
Sanctions and watchlist screening have never been more challenging, but new techniques that leverage open source data and machine learning are fortunately now available that can help significantly improve their efficiency and reliability, with a reduction in false positives that can make a 4X improvement in operational productivity without increasing non-compliance risks.